중복행 확인 (duplicated)
DataFrame.duplicated(subset=None, keep='first')
duplicated : 중복되는 행을 확인
행의 모든 요소가 동일한 행이 이미 존재할경우 해당 행은 True로 반환
df.duplicated(subset=None, keep='first')
subset : 특정 열만을 대상으로 할 수 있습니다. list의 사용도 가능합니다.
keep : {first : 위부터 검사 / last : 아래부터 검사} 검사 순서를 정합니다. first일 경우 위부터 확인해서 중복행이 나오면 True를 반환하며, last일 경우 아래부터 확인합니다.
예시
df = pd.DataFrame({'Num':[1, 2, 1, 2, 2, 3],
'Alphabet':['a', 'b', 'a', 'b', 'a', 'b']})
df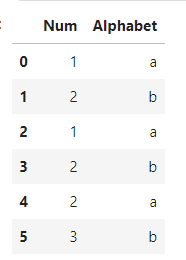
keep='first'이며 위에서부터 행을 확인하여 중복인 행이 나오면 True를 반환
print(df.duplicated(keep='first'))
keep='last'일 경우 아래부터 행을 확인하여 중복인 행이 나오면 True를 반환
print(df.duplicated(keep='last'))
아래 행 부터 확인 하였으므로 0,1번째 행 데이터가 아래 2,3번째 행의 중복 데이터가 된다.
subset으로 특정 열만 확인
print(df.duplicated(subset=['Alphabet']))
중복행 제거 (drop_duplicates)
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
drop_duplicates : 내용이 중복되는 행을 제거하는 메서드
df.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False)
subset : 중복값을 검사할 열 입니다. 기본적으로 모든 열을 검사합니다.
keep : {first / last} 중복제거를할때 남길 행입니다. first면 첫값을 남기고 last면 마지막 값을 남깁니다.
inplace : 원본을 변경할지의 여부입니다.
ignore_index : 원래 index를 무시할지 여부입니다. True일 경우 0,1,2, ... , n으로 부여됩니다.
예시
df = pd.DataFrame({'Num':[1, 2, 1, 2, 2, 3],
'Alphabet':['a', 'b', 'a', 'b', 'a', 'b']})
df
df.drop_duplicates()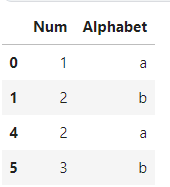
0,1번째 행과 중복된 2,3번재 행 제거
subset에 특정 컬럼명만 입력할 경우, 해당 열에대해서만 중복값 검사를 수행
df.drop_duplicates(subset='Num')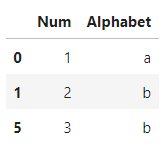
keep인수를 통해 남길 행 선택
keep='first'인 경우 처음 값을 남깁니다. (기본값)
df.drop_duplicates(subset='Num', keep='first')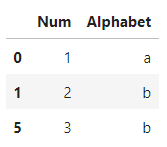
keep='last'인 경우 마지막 값을 남깁니다.
df.drop_duplicates(subset='Num', keep='last')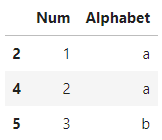
추가로 ignore_index=True로 할 경우 결과값의 인덱스를 0, 1, 2, ... , n으로 설정합니다.
df.drop_duplicates(subset='Num', keep='last',ignore_index=True)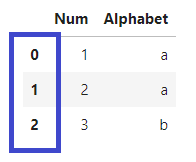
위의 결과와 동일하지만 인덱스가 바뀐 것을 볼 수 있다.
inplace 인수의 사용
Pandas 공통사항으로 inplace인수를 사용할 경우 원본에 변경이 적용
df.drop_duplicates(subset='Num',inplace=True)
print(df)
참조: https://wikidocs.net/154060
09-07. 중복행 제거 (drop_duplicates)
####DataFrame.drop_duplicates(subset=None, keep='first', inplace=False, ignore_index=False) ##개요 `d…
wikidocs.net
12-08 중복행 확인 (duplicated)
####DataFrame.duplicated(subset=None, keep='first') ##개요 `duplicated` 메서드는 중복되는 행을 확인하는 메서드입니다. 행의 …
wikidocs.net
'Study > Python' 카테고리의 다른 글
| [pandas] 데이터프레임 행 이동하기 .shift() (0) | 2023.06.15 |
|---|---|
| [pandas] .resample 시계열 자료 시간간격 리샘플링하기 (1) | 2023.06.13 |
| [python] 데이터프레임 병합하기 pd.merge() (0) | 2023.06.10 |
| [python] read_csv로 데이터 불러올 시 parse_dates 옵션으로 datetime 형태로 지정하기 (0) | 2023.06.09 |
| [python] 인덱스를 열로 변환 (reset_index) (0) | 2023.06.06 |